OpenAI představilo lehčí verzi 4o (oznam zde). GPT-4o mini je o 60 % levnější než GPT-3,5 Turbo. Slušný!
Cena modelu je 0,15 USD za milion vstupních tokenů a 0,60 USD za milion výstupních tokenů (~2500 stran knihy). Pro srovnání, GPT-3.5-turbo-0301 stál před zhruba více než rokem 2,00 USD za 1 milion tokenů.
Zatím to vypadá, že model je dobrý ve strukturování informací i porozumění dlouhému kontextu.
Meta záhy poté právě vydala Llama 3.1 , svůj dosud největší open-source model umělé inteligence, a tvrdí, že v testech překonává GPT-4o i Claude 3.5 Sonnet.
Délka kontextu 128k, umí chatovat v osmi jazycích, psát lepší počítačový kód a řešit složitější matematické úlohy. Má 405 miliard parametrů trénována na 16 000 GPU H100 od Nvidia.
Jen open source, lze vyzkoušet na Hugging Face přes web. Omylem jsem si ho pustil na svém iMacu, kde mám jen 8 GB RAM a bylo vidět hned, co moderní AI na lokále potřebuje: mraky paměti …
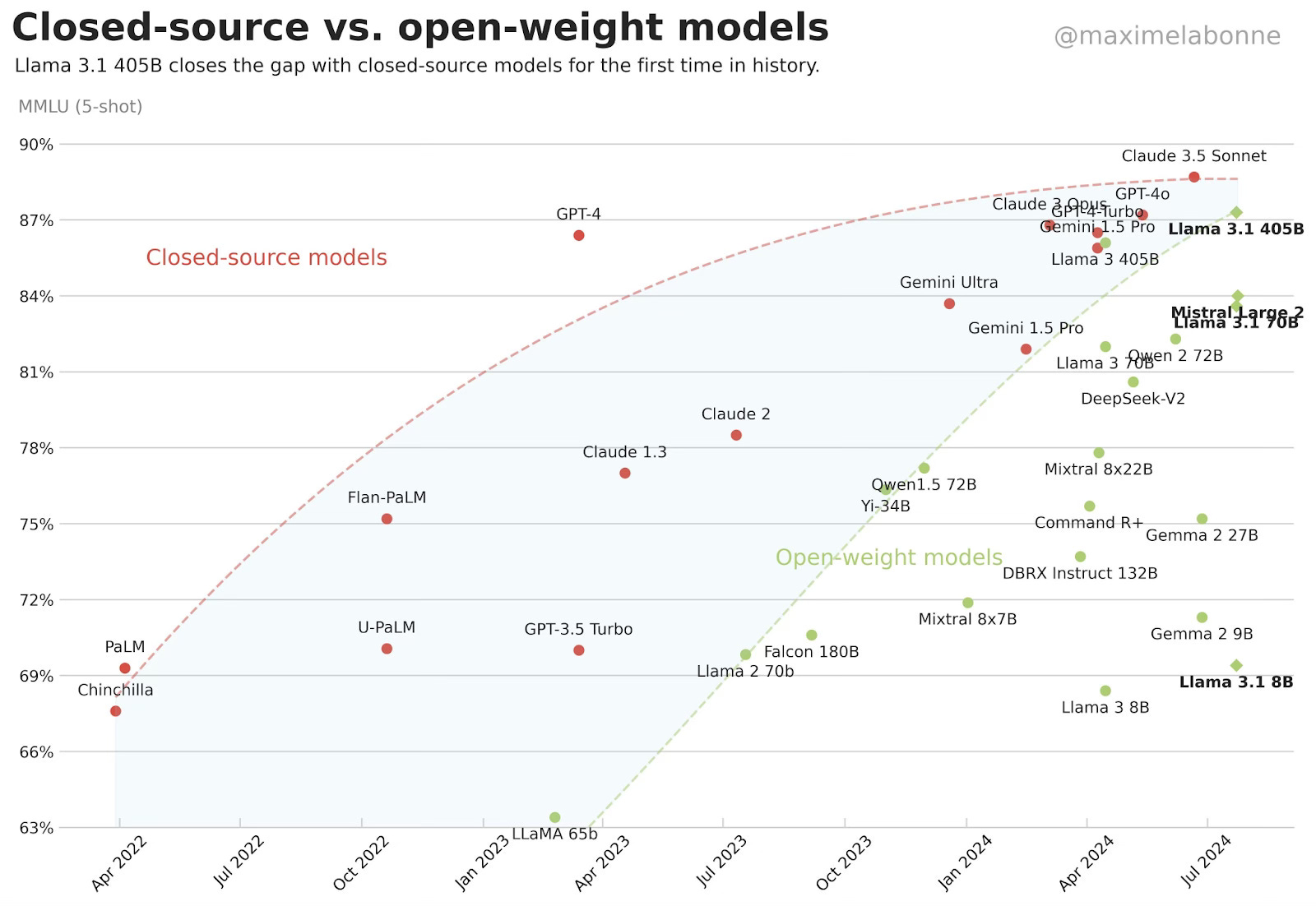
A do třetice - hned po oznámení Mety se přihlásil i francouzský Mistral se svým open source LLM modelem, když vydal Mistral Large 2 , novou verzi největšího modelu firmy. Mistral Large 2 je model s parametry 123B s kontextovým oknem 128k. V mnoha benchmarcích (zejména v generování kódu a matematice) je podle tvrzení Mistralu lepší nebo na stejné úrovni jako Llama 3.1 405B. Stejně jako Mistral NeMo byl trénován na velkém množství zdrojového kódu a vícejazyčných dat. Firemní oznámení je zde.
Co je na tom podstatné? Zdá se, že Mistral s menšími modely dosahuje velmi podobných výsledků, jako Llama, což otevírá dveře lepší ekonomice provozu. Na grafu je vidět, jak si jednotlivé modely stojí proti testu MMLU a jak open source modely stahují ztrátu za modely uzavřeného kódu: