
Google se v poslední době hodně snaží a s umělou inteligencí posouvá. Před dvěma týdny vydal model Ultra 1.0, minulý týden pak model Gemini Pro 1.5. Budeme si muset trochu udělat pořádek v Google AI modelech, ale nebojte, ještě to chvilku počká, protože Google je nejdříve oznamuje a veřejné uvolnění mu trvá, tím spíše pro Českou republiku. Co je ale důležité: Google opouští značku Bard a své nové LLM modely označuje jako Gemini.
A teď k novému modelu Gemini Pro 1.5. Ten nemá mít tolik parametrů, tedy takový rozsah, jako model Gemini Ultra oznámený před týdnem, hlavní výhodou Gemini Pro 1.5 má být velikost kontextového okna. Ta má být až deset milionů tokenů. A to jsou dvě věty, u kterých se zastavíme, abychom si to vysvětlili.
Tak za prvé: co je to token? Token je významové slovo v rámci LLM modelu. Odpovídá zhruba lidskému slovu, jde ale o číselnou reprezentaci slova s rozlišením jeho významu. Pokud může mít jedno stejně písmenně zapsatelné slovo více významů, má také více tokenů. Slovo hra má jeden token, pokud je divadelní, jeden, pokud je počítačová a další, pokud je to dětská hra. Velké jazykové modely se tak vyrovnávají s nejednoznačností lidského jazyka, kterou převádějí na matematickou jednoznačnost.
Za druhé, co je to kontextové okno? To je v zásadě délka “promptu”, tedy dotazu či úkolu a všech příslušných dat, které zadáváte jako dotaz jazykovému modelu. Starší modely v dávnověku (předloni a vloni) uměly pracovat s rozsahem desítek, maximálně stovek tokenů kontextu. Situaci významně změnil model Claude od společnosti Anthropic loni v létě, kdy nabídl nejprve 100 000 tokenů a později ještě dvojnásobek, pak GPT Turbo zvedl standard na 128k tokenů.
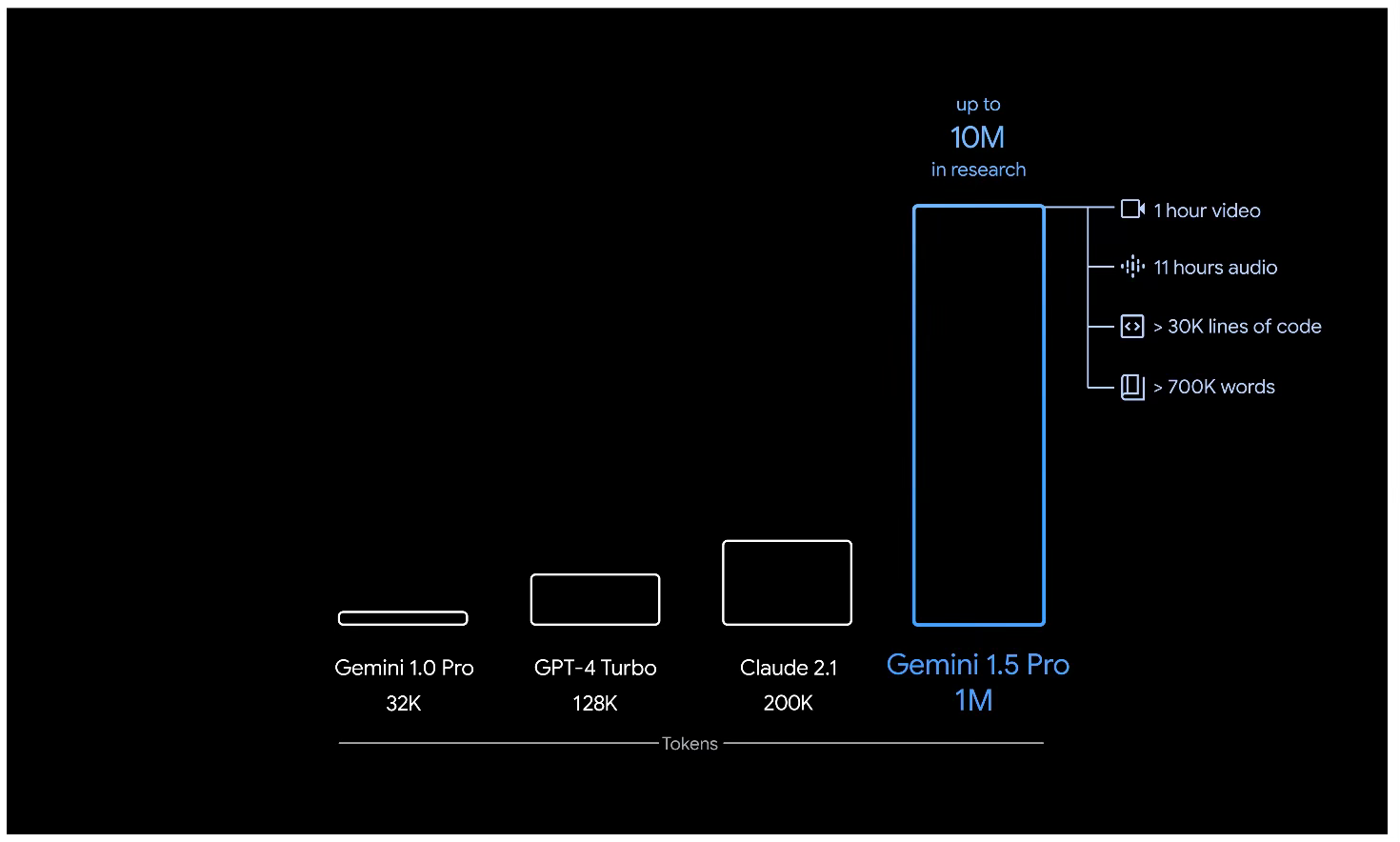 Velikost kontextového okna u modelu Gemini 1.5 Pro ve srovnání s ostatními LLM
Velikost kontextového okna u modelu Gemini 1.5 Pro ve srovnání s ostatními LLM

Proč je to důležité? Protože délka kontextu rozhoduje o tom, kolik dat můžete předat do AI v rámci “dotazu”. Všechno ostatní je totiž zapomenuto nebo zmateno. Jasně, na větu “vymysli vtip obsahující čecha, maďara a slováka” si vystačíte s velmi malou délkou kontextu, jenže promptem je potřeba předávat knihy nebo i celá videa u multimodálních modelů. A jen delší kontext umožňuje předat PDF knihy do AI nebo dokonce video a nechat jej AI zpracovat jinak, než přes natrénování. Do AI tak můžete nacpat i velmi dlouhá data a nechat je nějak zpracovat, například zanalyzovat. A to je hodně důležitý první moment.
Druhý důležitý moment dlouhého kontextu je, že takto vložená data jsou předpokladem pro univerzální umělou inteligenci (AGI). Ta se díky takto vkládaným podkladům může naučit vykonávat nové úkoly, které dosud neuměla. Příkladem může být experiment s Gemini Pro, které mohlo překládat texty z pramálo používaného jazyka jen poté, co mu byla dána mluvnice dotyčného jazyka. Dlužno ovšem dodat, že Gemini zřejmě tento kontext nezahrnuje do jazykového modelu, může ho použít pouze tady a teď. Naopak ChatGPT zavedl zanášení dat z promptů do historie, ovšem zřejmě jde jen o jednu z vrstvev v transformátoru, která při průchodu promptu do LLM obohatí prompt o historický kontext, například o to, že chcete, aby se vždy GPT vyjadřovalo žertovně.
Podstatnou informací ovšem je, že rozsáhlejší kontextové okno zpřístupňuje Google respektive DeepMind zatím jen některým uživatelům a nejsou úplně přesvědčivé podklady o tom, jak to funguje, takže na širší zhodnocení je příliš brzy. Zatím jen počítejme s tím, že se blízká na lepší časy!
Tohle je podstatná novinka z modelu Gemini Pro, která stojí za jeho radikálním zlepšením: funkce nazvaná Mixture of Experts (MoE).
Architektura Mixture of Experts (MoE) představuje pokročilý přístup k navrhování a trénování hlubokých neuronových sítí. Mixture of Experts modely jsou založeny na ideji, že místo jedné velké neuronové sítě, která se snaží naučit se všechny aspekty úkolu, je efektivnější použít soubor menších “expertních” modelů, kde každý expert se specializuje na určitou část úkolu. Výsledný model poté dynamicky vybírá a kombinuje výstupy těchto expertů na základě vstupních dat.
Jak architektura MoE funguje?
Rozdělení na Expertní Modely: V MoE architektuře je úkol nebo dataset rozdělen mezi různé expertní modely. Každý z těchto modelů je trénován na specifické části úlohy nebo dat, díky čemuž se stává “expertem” v určité oblasti.
Vrstva Brány čili Gateway: Na začátku modelu stojí vrstva zvaná “gateway” nebo také “dispatcher”, která rozhoduje, jaké expertní modely budou pro daný vstup použity. Tato vrstva analyzuje vstupní data a na základě toho dynamicky směruje data k relevantním “expertům”.
Kombinace Výstupů: Po zpracování vstupních dat expertními modely se výstupy těchto modelů kombinují. Tato kombinace se obvykle provádí pomocí váhování, kde větší váha je přiřazena výstupům od expertů, které systém považuje za nejrelevantnější pro daný vstup.
Učení a Optimalizace: Celý systém je trénován end-to-end, což znamená, že se učí nejen samotné expertní modely, ale také mechanismus, který rozhoduje, jak data rozdělit mezi experty a jak kombinovat jejich výstupy.
Škálovatelnost a Efektivita: Jednou z hlavních výhod MoE je, že umožňuje modelu škálovat efektivněji, protože není nutné, aby každý expert byl aktivní pro každý vstup. To znamená, že lze trénovat mnohem větší modely, aniž by došlo k exponenciálnímu nárůstu výpočetních nároků.
Podobnou technologii údajně používá i GPT-4 nebo opensource LLM Mistral. MoE je zatím přítomné jen v Gemini Pro, zajímavé by bylo sledovat, co udělá, až/pokud bude nasazen v Gemini Ultra.
